
MAPEO DE LA SUPERFICIE DE AGUA: SÍNTESIS DEL MÉTODO
This section presents a resume of the method developed and applied by MapBiomas Agua. For more information on the methodological details,visit ATBD (Algorithm Theory Base Document)
Presentation
El objetivo de MapBiomas Agua es proporcionar datos anuales y mensuales sobre la dinámica de la superficie de agua y los cuerpos de agua en todo el territorio nacional desde 1985, y distinguir entre cuerpos de agua naturales y antropogénicos (presas pequeñas y grandes, agua en zonas mineras). El conjunto de datos están disponibles públicamente en una platform web para mejorar la gestión y el uso de los recursos hídricos.
El mapeo de superficie de agua en Bolivia utilizó todas las escenas del satélite Landsat con una cobertura de nubes menor o igual al 70% y una resolución espacial de 30 metros. El mapeo fue conducido a una escala de sub-píxel (SWSC), con Análisis de Mixtura Espectral (SMA – por sus siglas en inglés) y reglas de clasificación empíricas basadas en una lógica fuzzy. El mapeo comprendió el periodo de 1985 a 2024, en la escala mensual, con más de 396.000 escenas Landsat procesadas y analizadas en la plataforma Google Earth Engine.
Organization and database
La coordinación general de MapBiomas Agua es conducida por Imazon y RAISG mientras que la coordinación técnica y operacional es dirigida por Geokarten. La reconstrucción de la serie histórica mensual de superficie de agua fue conducida por especialistas de todos los biomas de los países amazónicos, con el liderazgo de las siguientes instituciones: Fundación Amigos de la Naturaleza -FAN- (Bolivia), Fundación Gaia Amazonas -FGA- (Colombia), EcoCiencia (Ecuador), Instituto del Bien Común -IBC- (Perú), Provita y Wataniba (Venezuela), Alliance of Bioversity International y CIAT (Guianas y Suriname). El algoritmo de mapeo de superficie de agua fue desarrollado por Imazon y adaptado por MapBiomas Agua en esta primera etapa de trabajo.
The development of the MapBiomas Agua dashboard was led by Geodatin and has relevant contributions from the MapBiomas Agua working group and platform users in the design thinking process.
Fueron producidos 4 tipos de productos por MapBiomas Agua:
- Monthly and annual water surface maps;
- Water surface transition maps between “Water” and “Non-Water” classes. This product was processed with the annual water surface database;
- Trend maps (increase and decrease) of water surface. This product was calculated from monthly water surface data in 5 km x 5 km grids.
- Mapas de tipos de cuerpos de agua: naturales, antropogénicos, hidroeléctricos, mineros y acuicultura.
The dashboard está compuesto por mapas, estadísticas y herramientas de visualización, análisis y acceso a los datos. Es posible visualizar los datos en escala anual y mensual, más allá de obtenerlo en distintas unidades territoriales. Para finalizar, el dashboard también dispone un link de acceso a la API de los datos de MapBiomas Agua.
Method
El siguiente diagrama ilustra las principales etapas en el proceso de clasificación de la superficie de agua en los países amazónicos, y comprende de un clasificador de aguas superficiales a nivel de subpíxel (SWSC), árboles de decisión y procedimientos de post-clasificación para generar un conjuntos de datos anuales y mensuales de aguas superficiales.
Figure 1. Classification steps of the water surface and water bodies
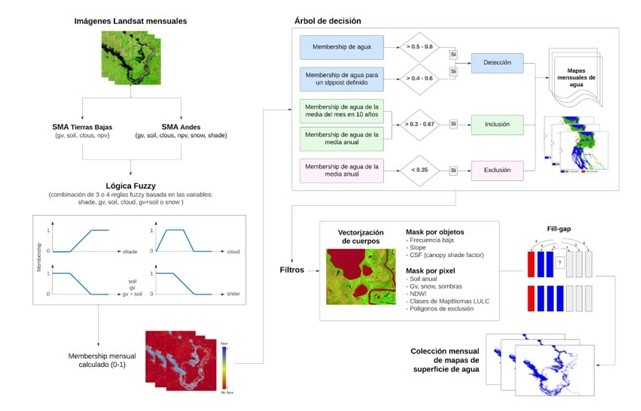
Description of classification steps:
- Pre-processing
Consists in the selection of Landsat scenes from the sensors: Landsat 5 Thematic Mapper (TM), Landsat 7 Enhanced Thematic Mapper Plus (ETM+), and Landsat 8 Operational Land Imager (OLI); applying cloud and shadow masking to each scene and excluding scenes with more than 70% cloud cover. The visible, near and mid-infrared spectral bands were selected for the application of the Mixture Spectral Model (MEM). The result of the MEM is a set of compositional bands for each pixel of the Landsat image, for the Vegetation, Non-Photosynthetically Active Vegetation (NPV), Soil, Shade, and Cloud components. Water behaves as a dark body (i.e. low reflectance) in Landsat images and therefore has a high percentage of the Shadow component in the pixel. The edges of lakes, rivers, and humid environments, such as floodplains, present a mixture of Shadow (water), Vegetation, and Soil, which allows the detection of water in environments with these types of materials.
- Water Surface Classification
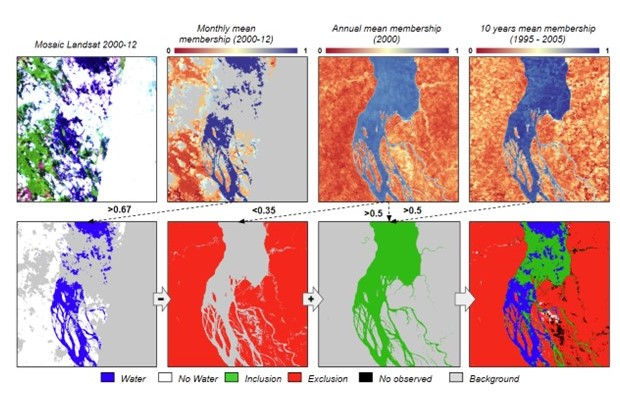
El algoritmo clasificador de sub-pixel de agua superficial (SWSC) original utiliza tres reglas jerárquicas de decisión binaria (ej. verdadero, falso). Debido a que el agua absorbe gran parte de la radiación electromagnética se utiliza una imagen con fracción de Shade, la combinación de GV y Soil y Cloud para clasificar los píxeles como agua superficial. Adicionalmente, se aplica una clasificación basada en lógica difusa (reglas fuzzy) independientes, en las que se determina el grado de verdad/certeza (memberships) de que un pixel Landsat es clasificado como agua. Luego se calculó el grado de verdad promedio para obtener un mapa continuo de membership con valores que oscilan entre 0 y 1. En base a estos memberships se clasifican los píxeles para producir capas de agua superficiales mensuales.
By calculating the median pixel memberships among available Landsat scenes for each month, pixels were classified as water based on defined thresholds. Procedures were then applied to restore false negatives and remove false positives, based on temporal metrics. Gap filling was then applied to reclassify as water those pixels that were eventually covered by clouds or within areas where no Landsat scenes existed during a given month, using a combination of two rules: within-year median probability and the decadal median. of the corresponding month. Finally, the presence of cloud shadows or other dark objects in the Landsat scene can also produce false positives in the water classification, so a removal filter was applied to reclassify those pixels as non-water.
Annual surface water maps include an identification between permanent and seasonal water, this classification is based on thresholds corresponding to the number of months in which a pixel is classified as water. For the first case, a frequency >= 6 months is considered, and for the second, a frequency between 1 to 5 months.
Figure 2. Monthly classification process.
- Clasificación de Cuerpos Hídricos
Figura 3. Proceso de clasificación de cuerpos hídricos.
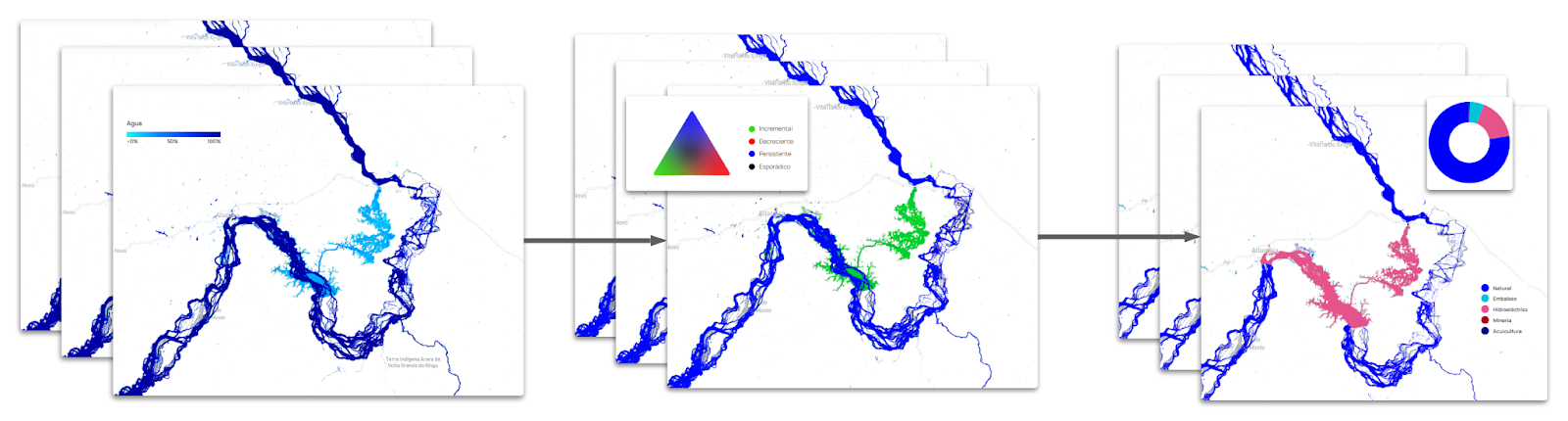
Para la clasificación de cuerpos hídricos se utilizaron las siguientes informaciones extraídas del mapeo anual de superficie de agua (permanente): i) la primera y la última ocurrencia del cuerpo hídrico del año, ii) la frecuencia total de la superficie de agua de la serie histórica y iii) la frecuencia anual. Esta información fue organizada en datos matriciales y utilizados en un algoritmo de segmentación de objetos.
Posteriormente, se extrajeron atributos de mapas auxiliares de hidroeléctricas y minería de las siguientes entidades:
- MapBiomas Amazonía Colección 6
- MapBiomas Bolivia Colección 2
Los segmentos de cuerpos hídricos fueron clasificados mediante el algoritmo Random Forest en cinco categorías: natural, otros artificiales, hidroeléctrica, minera y de acuicultura. Adicionalmente, se incluyó una clase de “falsos positivos” para eliminar sobreestimaciones persistentes en los mapas de superficie anual y mensual. Posteriormente, se aplicaron filtros espaciales y de frecuencia; además, se tomaron muestras adicionales y se delinearon polígonos manuales para mejorar el resultado.